Brian Alibali
Lead Developer Full-Stack
MeshScraper — Comment j'ai créé un outil d'audit SEO du maillage interne
En tant que développeur web, je suis sensible aux enjeux SEO. Mais quand j’ai voulu auditer le maillage interne de mes sites, j’ai vite déchanté : 100 à 500€/mois pour des outils comme Screaming Frog ou Ahrefs. Pour un freelance qui veut juste visualiser comment ses pages sont reliées entre elles, c’est disproportionné. Alors j’ai créé le mien.
Le problème : un levier SEO invisible et sous-exploité
Le maillage interne, c’est l’ensemble des liens qui relient les pages d’un même site entre elles. C’est un levier SEO puissant mais souvent négligé, parce qu’il est difficile à visualiser.
Les symptômes d’un mauvais maillage sont concrets :
- Des pages orphelines que Google ne trouve jamais
- Une profondeur excessive : certaines pages à 5 ou 6 clics de la homepage
- Des liens cassés qui gaspillent du budget de crawl
- Aucune cohérence sémantique entre les pages liées
Le problème avec les outils existants ? Soit ils sont chers, soit ils ne filtrent pas les liens par zone. Un lien dans le footer qui apparaît sur 200 pages n’a pas la même valeur qu’un lien contextuel placé dans le corps d’un article. Aucun outil ne faisait cette distinction de manière visuelle et accessible.
MeshScraper : ce que ça fait
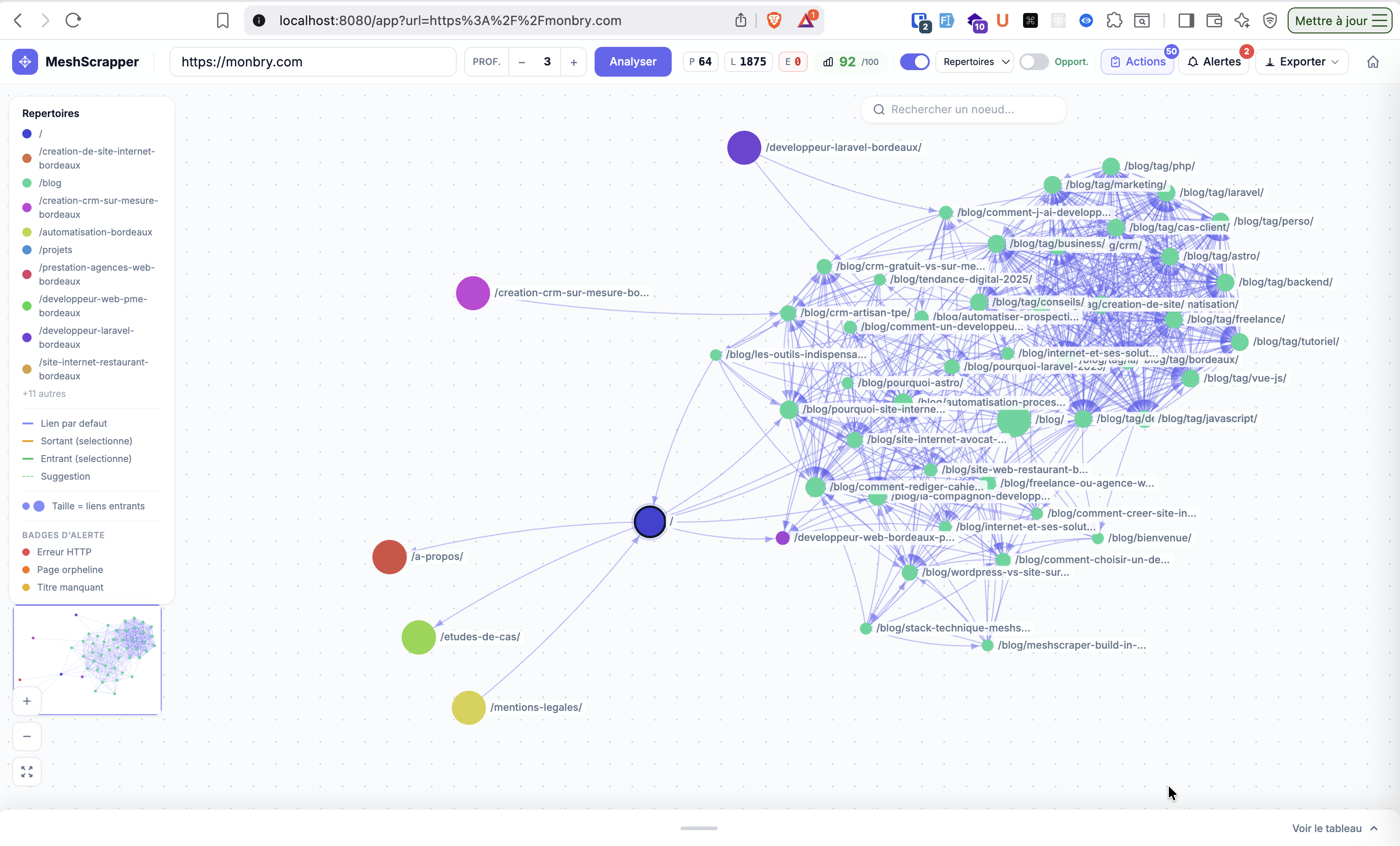
MeshScraper est un outil d’audit SEO du maillage interne. On entre une URL, il crawle le site et génère un graphe interactif qui montre les relations entre les pages, en se focalisant sur les liens dans le corps de texte.
Crawl intelligent
Le crawler fonctionne en BFS (Breadth-First Search), respecte le robots.txt et utilise un throttle adaptatif pour ne pas surcharger le serveur cible. Il distingue automatiquement les liens de navigation (header, footer, sidebar) des liens dans le contenu — c’est le différenciateur clé de MeshScraper.
Graphe interactif
Le graphe est rendu en Canvas avec D3.js : zoom, drag, minimap, recherche de nœuds, coloration par profondeur. On voit instantanément quelles pages sont bien maillées et lesquelles sont isolées.
Alertes SEO automatiques
MeshScraper détecte 7 types d’alertes :
- Pages orphelines (aucun lien entrant dans le contenu)
- Profondeur excessive (plus de 3 clics depuis la homepage)
- Liens cassés (erreurs HTTP 4xx/5xx)
- Titres manquants ou dupliqués
- Meta descriptions absentes
- Pages sans lien sortant
- Redirections en chaîne
Score de maillage /100
Un score global sur 100 évalue la qualité du maillage interne selon 5 axes : couverture, profondeur, réciprocité des liens, distribution et santé technique. Un score précis, pas juste un feu vert ou rouge.
Suggestions TF-IDF
MeshScraper analyse le contenu textuel des pages avec TF-IDF (scikit-learn) et suggère des liens à créer entre pages sémantiquement proches qui ne sont pas encore reliées. Des suggestions concrètes et actionnables.
Plan d’action priorisé
Toutes les alertes et suggestions sont regroupées dans un plan d’action classé par priorité. On sait exactement par quoi commencer.
Exports
Export des données en CSV, du rapport en HTML et du graphe en PNG. Pratique pour partager avec un client ou archiver un audit.
Les choix techniques
Backend : Python 3.13, FastAPI, httpx
Le backend tourne sur Python 3.13 avec FastAPI. Le crawl utilise httpx en mode asynchrone pour paralléliser les requêtes, et lxml pour le parsing HTML — nettement plus rapide que BeautifulSoup. L’analyse sémantique repose sur scikit-learn pour le TF-IDF.
Frontend : Vanilla JS, D3.js, Canvas
Zéro framework frontend. Tout est en Vanilla JS avec D3.js v7 pour le graphe et Tailwind CSS via CDN pour le styling. Pas de bundler, pas de node_modules. Un choix radical mais assumé : le frontend est léger, rapide, et n’a aucune dépendance à maintenir.
Le graphe est rendu en Canvas plutôt qu’en SVG. Au-delà de quelques centaines de nœuds, SVG rame. Canvas gère des milliers de nœuds sans broncher.
Infrastructure
Docker + Gunicorn + Uvicorn pour le déploiement. L’application est stateless : pas de base de données, pas de comptes utilisateurs. Le crawl est lancé, les résultats sont retournés, point.
L’évolution depuis la v1
La première version utilisait Nuxt.js côté front, Scrapy + BeautifulSoup côté back, et le graphe était en SVG. Ça fonctionnait, mais c’était lourd. J’ai tout repris :
- Nuxt → Vanilla JS : plus simple, plus léger, plus rapide à itérer
- Scrapy → httpx : plus de contrôle sur le crawl asynchrone
- BeautifulSoup → lxml : parsing 10x plus rapide
- SVG → Canvas : performance graphe sur les gros sites
- Ajout de scikit-learn : suggestions TF-IDF
Le résultat : une application plus rapide, plus maintenable, avec plus de fonctionnalités.
L’origine du projet
J’ai un frère, Kevin Alibali, consultant SEO. En discutant de son quotidien, un constat revenait souvent : les outils d’audit SEO sont chers et souvent overkill pour des freelances ou des petites agences qui veulent juste vérifier leur maillage interne.
L’idée de MeshScraper est née de là : créer un outil gratuit et visuel, qui fait une seule chose mais qui la fait bien. Et pour moi, c’était l’occasion de monter en compétences sur Python, FastAPI, D3.js et l’analyse de données textuelles.
Ce que j’ai appris
Ce projet m’a appris énormément :
- L’architecture d’un crawler : gestion du throttle, du BFS, des redirections, du robots.txt
- Le rendering Canvas avec D3.js : les pièges de performance, la gestion des événements sur Canvas vs DOM
- Le NLP appliqué : TF-IDF, similarité cosinus, et comment en tirer des suggestions concrètes
- L’importance de la simplicité : supprimer Nuxt, supprimer le bundler, tout réécrire en Vanilla JS a rendu le projet 10x plus maintenable
- La complexité du SEO technique : scorer un maillage interne oblige à comprendre en profondeur les critères qui comptent
Et surtout : le meilleur moment pour réécrire un projet, c’est quand on comprend enfin ce qu’il aurait dû être dès le départ.
La suite
L’outil n’est pas encore en ligne, mais la publication est imminente. MeshScraper continue d’évoluer, et voici ce qui est prévu :
- Mise en ligne publique (très bientôt)
- Authentification et espace utilisateur
- Historique des crawls et diff entre deux audits
- Rapport PDF white-label pour les consultants SEO
- Détection de clusters thématiques automatique
- Crawl programmé avec alertes par email
Conclusion
MeshScraper, c’est la preuve qu’on peut créer un outil utile sans budget, juste avec de la curiosité et du temps. Si le maillage interne est un sujet qui vous parle, l’outil sera bientôt disponible gratuitement.
Et si vous cherchez un développeur pour créer un outil sur-mesure qui résout un vrai problème métier, discutons-en.

Brian Alibali
Lead Developer Full-Stack • 7 ans d'expérience
J'écris sur le développement web et les solutions techniques innovantes.